This is based on one of my previous analyses for my clients. My client has an IT support department which receives telephone calls for support request. The team providing support is limited due to budget constraints and needs to do also onsite support as well as the aforementioned remote support.
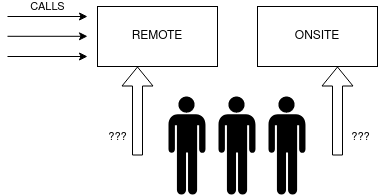
My client wants to know how many persons should be available to pickup telephone calls in certain periods (hour interval, days of the week, month) in order to properly assign the technicians to either provide remote support or go onsite. Too many people picking up calls and there’s not enought work for everybody and onsite support will encounter delays. Not enough people to pickup telephone calls and the service quality will suffer (and possibly bring also penalties stipulated in the contract).
The questions that need answering are:
- What are the overall characteristics of the remote support telephone calls?
- How many technicians are required to pick up calls to fulfill the required service?
Due to confidentiality of data, the data related to the calls is not real, however I tried as much as possible to respect the distribution of calls during the day, week and periods of the year. In all other aspects, such as column data format, the imaginary data that I’m using for this analysis example is accurate.
In the real situation, the telephone calls data came in XML format exported by an Alcatel-Lucent ACD and imported by another Python script in a SQLite database. The database was used for an in-house build telephone console to visualize call activity in near real-time.
ACD - An automated call distribution system, commonly known as automatic call distributor (ACD), is a telephony device that answers and distributes incoming calls to a specific group of terminals or agents within an organization.
Data import and cleaning
First thing first, the data needs to be imported from the SQLite database and loaded into a Pandas dataframe for analysis.
import sqlite3
from sqlite3 import Error
import pandas as pd
import numpy as np
def create_connection(path):
connection = None
try:
connection = sqlite3.connect(path)
print("Connection to SQLite DB successful")
except Error as e:
print(f"The error '{e}' occurred")
return connection
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"The error '{e}' occurred")
connection = create_connection("./call_journal.db")
Connection to SQLite DB successful
Data filtering sometimes starts with the SQL query. In my case, I’m only selecting data that I judged to be relevant to my analysis. However, it’s good to keep in mind that left out columns may contain relevant or crucial information. It’s best that in some cases the initial DB is reinvestigated to dig out more useful information.
select_call_records = '''
SELECT TicketType,
ChargedUserID,
SubscriberName,
CommunicationType,
Date,
Time,
DateTime,
CallDuration,
CallDurationMV,
RingingDuration
FROM call_journal'''
db_cols = ["TicketType",
"ChargedUserID",
"SubscriberName",
"CommunicationType",
"Date",
"Time",
"DateTime",
"CallDuration",
"CallDurationMV",
"RingingDuration"]
call_records = execute_read_query(connection, select_call_records)
df = pd.DataFrame(call_records, columns = db_cols)
display(df.sample(5))
| TicketType | ChargedUserID | SubscriberName | CommunicationType | Date | Time | DateTime | CallDuration | CallDurationMV | RingingDuration | |
|---|---|---|---|---|---|---|---|---|---|---|
| 42299 | Call | 15 | POSTE 6 | IncomingTransfer | 2020-05-18 | 14:25:00 | 2020-05-18 14:25:00 | 00:05:27 | 0:00:00 | 00:00:00 |
| 39961 | Call | 44 | POSTE 8 | Outgoing | 2020-03-11 | 08:39:00 | 2020-03-11 08:39:00 | 00:00:05 | 0:00:00 | 00:00:00 |
| 45878 | Call | 33 | MV 2 | IncomingTransfer | 2020-06-15 | 13:36:00 | 2020-06-15 13:36:00 | 0:00:00 | 00:00:04 | 00:00:00 |
| 36741 | Call | 19 | ACD | Incoming | 2020-02-21 | 14:04:00 | 2020-02-21 14:04:00 | 0:00:00 | 00:00:10 | 00:00:00 |
| 9003 | Call | 4 | POSTE 1 | IncomingTransfer | 2018-11-21 | 11:41:00 | 2018-11-21 11:41:00 | 0:03:16 | 0:00:00 | 0:00:06 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 63670 entries, 0 to 63669
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 TicketType 63670 non-null object
1 ChargedUserID 63670 non-null object
2 SubscriberName 63588 non-null object
3 CommunicationType 63670 non-null object
4 Date 63670 non-null object
5 Time 63670 non-null object
6 DateTime 63670 non-null object
7 CallDuration 63670 non-null object
8 CallDurationMV 63670 non-null object
9 RingingDuration 63670 non-null object
dtypes: object(10)
memory usage: 4.9+ MB
The important thing after data import is to try to understand what data is presented in the columns. Not being aware of what’s the purpose of the data or how it was generated could give innacurate results. I’ll come with examples below.
The documentation of the source of information (in my case the ACD) was the first step in understanding how it generates the data. After going through (way too many) documentation pages, I found the following:
- calls are registered as tickets in the ACD (tickets are single units of information of certain operations, like calls, agent activity etc.)
- calls are received first by SubscriberName ACD, then transfered to SubscriberName agents (POSTE 1, POSTE 2, MV etc.) for call pickup or sent to voicemail. This is a very important piece of information as the ACD registers once the call when it reaches the system and another ticket when it’s transfered and answered by the agent. Basically, the total number of calls is actually HALF. Example below
SubscriberName CommunicationType DateTime DialledNumber ACD Incoming 2019-11-28 10:38:00 0750.123.456 POSTE 1 IncomingTransfer 2019-11-28 10:38:00 0750.123.456
First, the call reaches ACD, then the same call gets transfered to agent (POSTE 1).
Call -- received --> ACD -- transfered --> POSTE 1
Since we are only interested in analyzing unique calls and not how they are routed, we need to drop all rows with SubscriberName == ACD to get the real numbers.
- The missed calls are not marked specifically. The call routing logic is that it’s either answered by someone or it’s redirected to voicemail.
SubscriberName CommunicationType DateTime DialledNumber ACD Incoming 2019-11-28 16:27:00 0750.123.456 MV 1 IncomingTransfer 2019-11-28 16:28:00 0750.123.456
The call reaches the ACD, no one can pickup the call, and the call is redirected to voicemail MV1.
Call -- received --> ACD -- transfered --> POSTE 1
Again, same history as before, for the same call, 2 tickets are made. We’ll drop the lines with SubscriberName = ACD
df = df.loc[df["SubscriberName"] != "ACD"]
Now, we’ll continue looking into the other columns.
df["TicketType"].unique()
array(['Call'], dtype=object)
Since “TicketType” doesn’t hold other values than “Call”, it has no value to us, so we’ll drop it.
df.drop(labels = ["TicketType"], axis = 1, inplace = True)
df["ChargedUserID"].unique()
array(['13', '14', '10', '33', '32', '44', '11', '15', '12', '59', '30', '42', '01', '04', '03', '05', '02', '06', '07', '08', '43'], dtype=object)
df["SubscriberName"].unique()
array(['POSTE 4', 'POSTE 5', 'POSTE 1', 'MV 2', 'MV 1', 'POSTE 8', 'POSTE 2', 'POSTE 6', 'POSTE 3', 'POSTE 7'], dtype=object)
df["CommunicationType"].unique()
array(['IncomingTransfer', 'Outgoing', 'OutgoingTransfer', 'OutgoingTransferTransit', 'IncomingTransferTransit'], dtype=object)
This will be filtered as well, as we’re only interested in incoming calls. One curious this is the “IncomingTransferTransit” value. We’ll check it out:
df.loc[df["CommunicationType"] == 'IncomingTransferTransit']
| ChargedUserID | SubscriberName | CommunicationType | Date | Time | DateTime | CallDuration | CallDurationMV | RingingDuration | |
|---|---|---|---|---|---|---|---|---|---|
| 2329 | 14 | POSTE 5 | IncomingTransferTransit | 2019-11-05 | 13:12:00 | 2019-11-05 13:12:00 | 00:00:09 | 0:00:00 | 00:00:00 |
Unfortunately, I could not find something relevand in the documentation and, since it’s only one value, we’ll drop it.
df = df.loc[df["CommunicationType"] != 'IncomingTransferTransit']
One last thing to check is for calls on Saturday and Sunday. During an initial run of this report, the data contained calls received on saturday and sunday.
df["Date"] = pd.to_datetime(df["Date"], format = "%Y-%m-%d")
df["Day_nb"] = df["Date"].dt.dayofweek
df = df.loc[~df["Day_nb"].isin([5,6])]
df.drop(labels = "Day_nb", axis = 1, inplace = True)
As a last check, we’ll look at the total values in columns, to check whether we need to dig deeper into the data.
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 44890 entries, 0 to 63668
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ChargedUserID 44890 non-null object
1 SubscriberName 44890 non-null object
2 CommunicationType 44890 non-null object
3 Date 44890 non-null datetime64[ns]
4 Time 44890 non-null object
5 DateTime 44890 non-null object
6 CallDuration 44890 non-null object
7 CallDurationMV 44890 non-null object
8 RingingDuration 44890 non-null object
dtypes: datetime64[ns](1), object(8)
memory usage: 3.4+ MB
All looks OK so far, we’ll proceed to setting the columns data types
Column data format
Next, we’ll set the proper type of certain columns
df["ChargedUserID"] = df["ChargedUserID"].astype("category")
df["SubscriberName"] = df["SubscriberName"].astype("category")
df["CommunicationType"] = df["CommunicationType"].astype("category")
df["Time"] = pd.to_datetime(df["Date"], format = "%H:%M:%S")
df["DateTime"] = pd.to_datetime(df["DateTime"], format = "%Y-%m-%d %H:%M:%S")
df["CallDuration"] = pd.to_timedelta(df["CallDuration"])
df["CallDurationMV"] = pd.to_timedelta(df["CallDurationMV"])
df["RingingDuration"] = pd.to_timedelta(df["RingingDuration"])
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 44890 entries, 0 to 63668
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ChargedUserID 44890 non-null category
1 SubscriberName 44890 non-null category
2 CommunicationType 44890 non-null category
3 Date 44890 non-null datetime64[ns]
4 Time 44890 non-null datetime64[ns]
5 DateTime 44890 non-null datetime64[ns]
6 CallDuration 44890 non-null timedelta64[ns]
7 CallDurationMV 44890 non-null timedelta64[ns]
8 RingingDuration 44890 non-null timedelta64[ns]
dtypes: category(3), datetime64[ns](3), timedelta64[ns](3)
memory usage: 2.5 MB
Data Analysis
We’ll start with some basic data exploration, to see some trends. Since we’re only interested in incoming calls, we’ll create a mask and filter the data
import altair as alt
mask_incoming = (df["CommunicationType"] == "IncomingTransfer")
df = df.loc[mask_incoming]
df["Answered"] = 0
df.loc[df["SubscriberName"].str.startswith('POSTE'), "Answered"] = 1
df.sample(5)
| ChargedUserID | SubscriberName | CommunicationType | Date | Time | DateTime | CallDuration | CallDurationMV | RingingDuration | Answered | |
|---|---|---|---|---|---|---|---|---|---|---|
| 59243 | 33 | MV 2 | IncomingTransfer | 2020-09-08 | 2020-09-08 | 2020-09-08 09:00:00 | 0 days 00:00:00 | 0 days 00:00:28 | 0 days 00:00:00 | 0 |
| 14136 | 5 | POSTE 6 | IncomingTransfer | 2019-03-06 | 2019-03-06 | 2019-03-06 10:37:00 | 0 days 00:03:44 | 0 days 00:00:00 | 0 days 00:00:06 | 1 |
| 45790 | 33 | MV 2 | IncomingTransfer | 2020-06-15 | 2020-06-15 | 2020-06-15 11:18:00 | 0 days 00:00:00 | 0 days 00:00:03 | 0 days 00:00:00 | 0 |
| 57021 | 32 | MV 1 | IncomingTransfer | 2020-08-26 | 2020-08-26 | 2020-08-26 08:45:00 | 0 days 00:00:00 | 0 days 00:00:05 | 0 days 00:00:00 | 0 |
| 830 | 13 | POSTE 4 | IncomingTransfer | 2019-07-25 | 2019-07-25 | 2019-07-25 08:49:00 | 0 days 00:03:47 | 0 days 00:00:00 | 0 days 00:00:00 | 1 |
Total calls per day
total_per_day = df.groupby("Date")["CommunicationType"].count().reset_index().rename({"CommunicationType": "Total"}, axis = 1)
total_per_day.sample(5)
| Date | Total | |
|---|---|---|
| 130 | 2019-04-18 | 47 |
| 409 | 2020-08-05 | 53 |
| 195 | 2019-07-26 | 66 |
| 329 | 2020-02-18 | 139 |
| 337 | 2020-02-28 | 53 |
alt.Chart(total_per_day).mark_trail().encode(
x = "Date:T",
y = 'Total',
size = 'Total:Q'
).properties(
width = 600
)
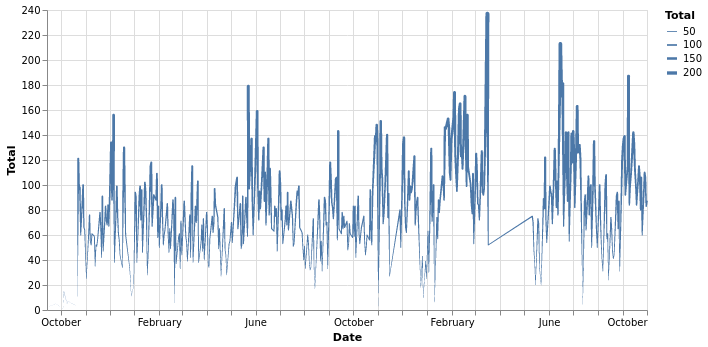
We can see that there is a huge chunk of data missing in April and May. The missing data is due to the 2020 COVID confinement.
Also, the chart is overcrowded, nothing is really visible here. Let’s remake it into a boxplot chart, to have more details.
boxplot = df.groupby("Date")["CommunicationType"].count().reset_index().rename({"CommunicationType": "Total"}, axis = 1)
boxplot["Date"] = pd.to_datetime(boxplot["Date"], format = "%H:%M:%S")
boxplot["YearMonth"] = boxplot['Date'].dt.to_period('M').dt.strftime('%Y-%m')
boxplot.sample(5)
| Date | Total | YearMonth | |
|---|---|---|---|
| 122 | 2019-04-08 | 75 | 2019-04 |
| 216 | 2019-08-28 | 68 | 2019-08 |
| 260 | 2019-10-29 | 135 | 2019-10 |
| 82 | 2019-02-11 | 85 | 2019-02 |
| 29 | 2018-11-23 | 47 | 2018-11 |
alt.Chart(boxplot).mark_boxplot().encode(
x='YearMonth:O',
y='Total:Q'
).properties(
width=600
)
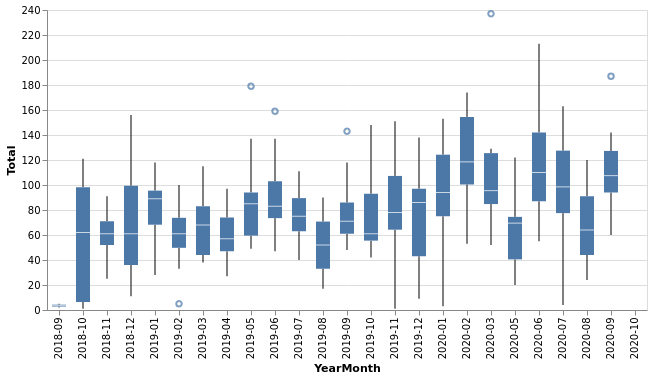
We can extract some info now:
- the average held between 60 to 100 in 2019, however the average ammount of calls increased in 2020.
- there is considerable variation in min / max calls from month to month (probably due to season variations) and this will require more precise estimates on manpower.
- there are outliers for max values, most likely indicating general incidents in the infrastructure that generate peak calls to the service. This should be adressed by an emergency service redirection.
Total calls per month - volume
total_per_month = df.groupby("Date")["CommunicationType"].count().reset_index().rename({"CommunicationType": "Total"}, axis = 1)
total_per_month.sample(5)
| Date | Total | |
|---|---|---|
| 130 | 2019-04-18 | 47 |
| 86 | 2019-02-15 | 49 |
| 262 | 2019-10-31 | 131 |
| 286 | 2019-12-17 | 68 |
| 302 | 2020-01-10 | 3 |
alt.Chart(total_per_month).mark_bar().encode(
x = "yearmonth(Date):O",
y = 'Total',
size = 'Total:Q'
).properties(
width = 600
)
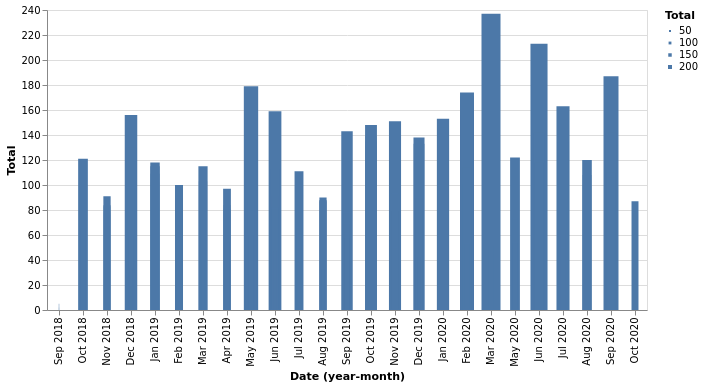
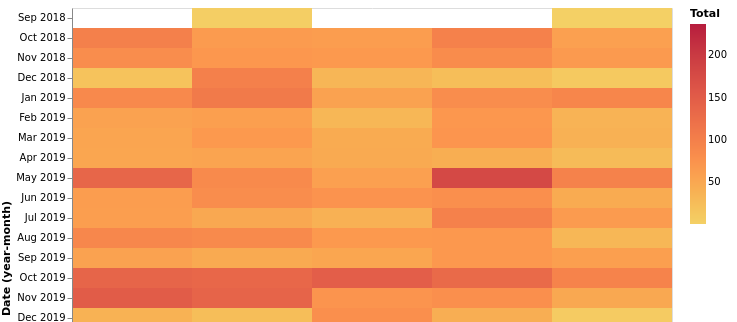
total_heatmap = df.groupby("Date")["CommunicationType"].count().reset_index().rename({"CommunicationType": "Total"}, axis = 1)
heatmap_per_day = alt.Chart(total_heatmap).mark_rect().encode(
x='date(Date):O',
y='yearmonth(Date):O',
color= alt.Color('Total:Q', scale=alt.Scale(scheme='goldred'))
).properties(
width=600
)
heatmap_per_day
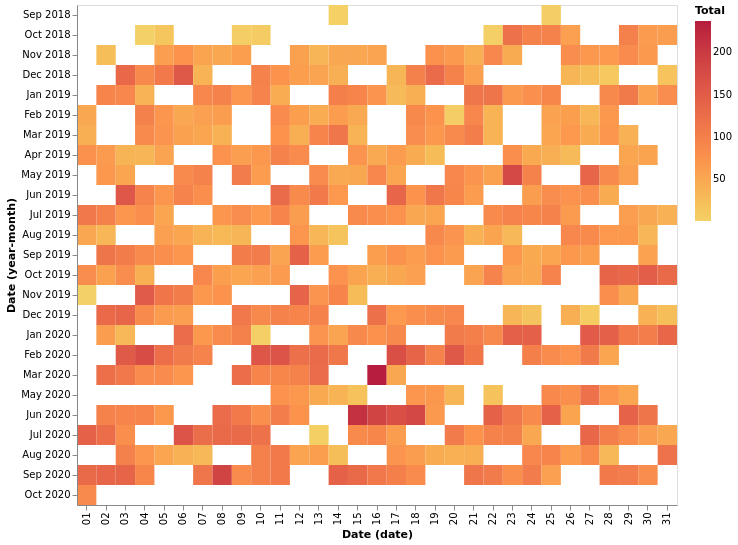
heatmap_per_day_of_week = alt.Chart(total_heatmap.rename({"CommunicationType": "Total"}, axis = 1)).mark_rect().encode(
x='day(Date):O',
y='yearmonth(Date):O',
color= alt.Color('Total:Q', scale=alt.Scale(scheme='goldred'))
).properties(
width=600
)
heatmap_per_day_of_week
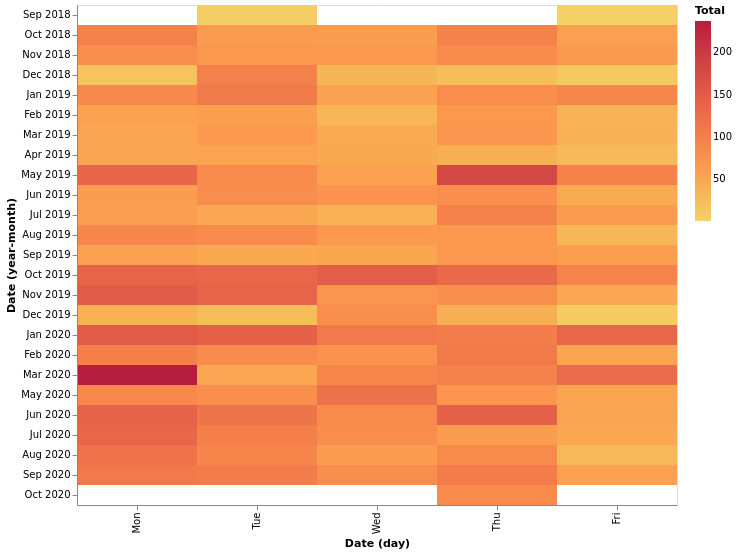
Estimator
Given a level of service, what is the minimum required ammount of agents to fulfill the service in question?
We’ll check this by constructing time intervals from calls start and end time and we’ll check at a certain frequency how many time intervals overlap. Since only one person can respond to a call, the total number of overlaps is the number of required agents.
Let’s look at a simple example:
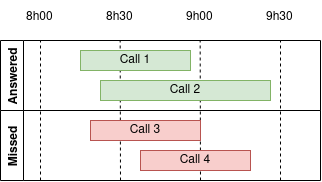
In the interval 8h00 - 8h30, we received 2 calls that were answered and we missed one call. In order to properly estimate the time occupation, we’ll add 5min (the average conversation time) to missed calls. So, for this interval, we needed 3 agents to answer. In the next interval, 8h30 - 9h00, we still have 2 agents on call (Call1 and Call2), we assume that there is another fictive agent on missed Call3 and we receive another call that we missed. In total, for this interval, we would need 4 agents. In total, we can see that we need:
| Interval | Agents needed |
|---|---|
| 8h00 - 8h30 | 3 |
| 8h30 - 9h00 | 4 |
| 9h00 - 9h30 | 2 |
The time interval to check for call status will be smaller (5 min) in order to be more precise in our results.
df["call_start_dt"] = df["DateTime"]
df["call_end_dt"] = np.nan
df.loc[df["Answered"] == 1, "call_end_dt"] = df["DateTime"] + df["CallDuration"]
average_call_time = df.loc[df["Answered"] == 1,"CallDuration"].mean()
average_call_time = average_call_time.floor("s")
average_call_time
Timedelta('0 days 00:05:11')
df.loc[df["Answered"] == 0, "call_end_dt"] = df["DateTime"] + pd.to_timedelta(average_call_time, unit = "S")
df.loc[:,("DateTime", "CallDuration", "call_start_dt", "call_end_dt")].sample(5)
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
def create_interval(df):
df["Time_interval"] = pd.Interval(df["call_start_dt"], df["call_end_dt"])
return df
df["Time_interval"] = np.nan
df = df.apply(create_interval, axis = 1)
df.loc[:("call_start_dt", "call_end_dt", "Time_interval")].head()
| call_start_dt | call_end_dt | Time_interval | |
|---|---|---|---|
| 0 | 2019-12-20 14:03:00 | 2019-12-20 14:12:43 | (2019-12-20 14:03:00, 2019-12-20 14:12:43] |
| 3 | 2019-12-20 14:27:00 | 2019-12-20 14:29:14 | (2019-12-20 14:27:00, 2019-12-20 14:29:14] |
| 4 | 2019-12-20 14:28:00 | 2019-12-20 14:30:07 | (2019-12-20 14:28:00, 2019-12-20 14:30:07] |
| 6 | 2019-12-20 14:35:00 | 2019-12-20 14:36:10 | (2019-12-20 14:35:00, 2019-12-20 14:36:10] |
| 10 | 2019-12-20 14:40:00 | 2019-12-20 14:41:45 | (2019-12-20 14:40:00, 2019-12-20 14:41:45] |
Constructing time intervals between date A and date B, each day with opening hour X and closing hour Y is … tricky :(
unique_date_list = df["Date"].unique()
date_range_start = []
date_range_end = []
frequency = pd.Timedelta("5 minutes")
for unique_date in unique_date_list:
day_range_start = pd.date_range(start = unique_date + pd.Timedelta("7 hours 30 minutes"),
end = unique_date + pd.Timedelta("18 hours 30 minutes") - frequency,
freq = frequency
)
day_range_end = pd.date_range(start = unique_date + pd.Timedelta("7 hours 30 minutes") + frequency,
end = unique_date + pd.Timedelta("18 hours 30 minutes"),
freq = frequency
)
date_range_start += day_range_start
date_range_end += day_range_end
verification_range = pd.IntervalIndex.from_arrays(date_range_start, date_range_end)
verification_range
IntervalIndex([(2019-12-20 07:30:00, 2019-12-20 07:35:00], (2019-12-20 07:35:00, 2019-12-20 07:40:00], (2019-12-20 07:40:00, 2019-12-20 07:45:00], (2019-12-20 07:45:00, 2019-12-20 07:50:00], (2019-12-20 07:50:00, 2019-12-20 07:55:00] ... (2020-10-01 18:05:00, 2020-10-01 18:10:00], (2020-10-01 18:10:00, 2020-10-01 18:15:00], (2020-10-01 18:15:00, 2020-10-01 18:20:00], (2020-10-01 18:20:00, 2020-10-01 18:25:00], (2020-10-01 18:25:00, 2020-10-01 18:30:00]],
closed='right',
dtype='interval[datetime64[ns]]')
result = []
for verification_interval in verification_range:
counter = 0
# we're filtering the main dataframe as there is no point in searching for overlaps in the next day
mask_filter_left = (df["call_start_dt"] > verification_interval.left - pd.Timedelta("24h"))
mask_filter_right = (df["call_end_dt"] < verification_interval.right + pd.Timedelta("24h"))
call_intervals = df.loc[(mask_filter_left & mask_filter_right), "Time_interval"]
for call_interval in call_intervals:
if verification_interval.overlaps(call_interval):
counter += 1
result.append({"time_interval": verification_interval,
"total_overlaps": counter})
estimator = pd.DataFrame(result)
estimator.sample(5)
| time_interval | total_overlaps | |
|---|---|---|
| 13575 | (2019-01-09 16:45:00, 2019-01-09 16:50:00] | 2 |
| 58858 | (2020-09-24 17:20:00, 2020-09-24 17:25:00] | 1 |
| 28128 | (2019-06-21 08:30:00, 2019-06-21 08:35:00] | 1 |
| 52824 | (2020-07-23 09:30:00, 2020-07-23 09:35:00] | 1 |
| 24577 | (2019-05-10 09:35:00, 2019-05-10 09:40:00] | 3 |
We got our results, but we’ll only keep the starting date of the interval, it’s much easier to construct graphs with simple dates than time intervals.
estimator["DateTime"] = estimator["time_interval"].apply(lambda x: x.left)
estimator = estimator.loc[:,("total_overlaps","DateTime")].rename({"total_overlaps": "Total"}, axis = 1)
estimator.sample(5)
| Total | DateTime | |
|---|---|---|
| 34381 | 1 | 2019-09-04 12:35:00 |
| 46296 | 2 | 2020-05-11 15:30:00 |
| 33707 | 2 | 2019-08-28 11:25:00 |
| 38821 | 3 | 2019-10-22 08:35:00 |
| 38847 | 1 | 2019-10-22 10:45:00 |
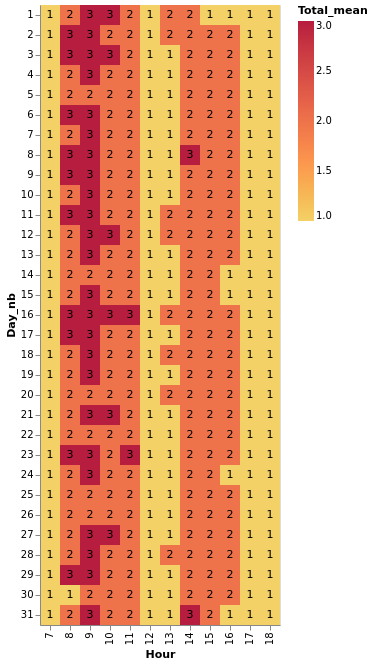
Average / Min / Max nb of agents required per hour per day
estimator["Hour"] = estimator["DateTime"].dt.hour
estimator["Day_nb"] = estimator["DateTime"].dt.day
estimator.sample(5)
| Total | DateTime | Hour | Day_nb | |
|---|---|---|---|---|
| 16620 | 0 | 2019-02-11 17:30:00 | 17 | 11 |
| 35779 | 0 | 2019-09-19 08:05:00 | 8 | 19 |
| 41340 | 6 | 2020-01-27 09:30:00 | 9 | 27 |
| 14365 | 1 | 2019-01-17 16:35:00 | 16 | 17 |
| 18406 | 1 | 2019-03-01 12:20:00 | 12 | 1 |
def calc_agg(df):
df["Total_mean"] = df["Total"].mean()
df["Total_mean"] = np.ceil(df["Total_mean"])
df["Total_min"] = df["Total"].min()
df["Total_max"] = df["Total"].max()
return df
heatmap_table = estimator.groupby(["Day_nb", "Hour"]).apply(calc_agg).reset_index(drop = True)
heatmap_table
| Total | DateTime | Hour | Day_nb | Total_mean | Total_min | Total_max | |
|---|---|---|---|---|---|---|---|
| 639 | 0 | 2019-12-27 16:45:00 | 16 | 27 | 2.0 | 0 | 5 |
| 33497 | 1 | 2019-08-26 15:55:00 | 15 | 26 | 2.0 | 0 | 10 |
| 46958 | 0 | 2020-05-18 15:40:00 | 15 | 18 | 2.0 | 0 | 6 |
| 43107 | 1 | 2020-02-13 13:45:00 | 13 | 13 | 1.0 | 0 | 7 |
| 56781 | 3 | 2020-09-03 09:15:00 | 9 | 3 | 3.0 | 0 | 9 |
alt.data_transformers.disable_max_rows()
base = alt.Chart(heatmap_table).encode(
x='Hour:O',
y='Day_nb:O'
)
color_avg = base.mark_rect().encode(
color= alt.Color('Total_mean:Q', scale=alt.Scale(scheme='goldred'))
)
text_avg = base.mark_text(baseline='middle').encode(
text = 'max(Total_mean):Q'
)
heatmap = color_avg + text_avg
heatmap